


Understanding Statistical Packet Multiplexing
 Sometimes I envy the UK. While America’s broadband regulator has been imposing harsh new rules on the Internet aimed at making it behave more like the old-fashioned telephone network, UK broadband regulator Ofcom did something the FCC should have done a year ago: commissioned a study of traffic management tools and techniques aimed at advising the regulator of the limits of its knowledge. A Study of Traffic Management Detection Methods & Tools by Predictable Network Solutions, does two things none of the FCC’s commissioned reports has ever done: explains the dynamics of statistical packet switching (the Internet’s foundation technology) and examines the shortcomings in every single one of the tools developed by academics and activist colleagues to detect traffic management.
Sometimes I envy the UK. While America’s broadband regulator has been imposing harsh new rules on the Internet aimed at making it behave more like the old-fashioned telephone network, UK broadband regulator Ofcom did something the FCC should have done a year ago: commissioned a study of traffic management tools and techniques aimed at advising the regulator of the limits of its knowledge. A Study of Traffic Management Detection Methods & Tools by Predictable Network Solutions, does two things none of the FCC’s commissioned reports has ever done: explains the dynamics of statistical packet switching (the Internet’s foundation technology) and examines the shortcomings in every single one of the tools developed by academics and activist colleagues to detect traffic management.
PNS is a consulting company that works with network operators to improve subjective service quality co-founded by Dr Neil Davies, one of a handful of people I’ve ever met who thoroughly understands the quality dynamics of broadband networks. The report begins with a the sharp contrast between circuit switching (telephone technology) and statistical packet multiplexing (SPM), the Internet’s technology, to wit:
The underlying communications support for ICT has also changed radically in the last 50 years. The dominant communications paradigm is no longer one of bits/bytes flowing along a fixed ‘circuit’ (be that analogue or TDM) like “beads on a string”. Today’s networks are packet/frame3 based: complete information units are split into smaller pieces, copies of which are ‘translocated’ to the next location…Each of these ‘store-and-forward’ steps involves some form of buffering/queueing. Every queue has associated with it two computational processes, one to place information items in the queue (the receiving action, ingress, of a translocation), the other to take items out (the sending action, egress, of a translocation). This occurs at all layers of the network/distributed application, and each of these buffers/queues is a place where statistical multiplexing occurs, and thus where contention for the common resource (communication or computation) takes place.
In practice, this means no broadband provider can ever guarantee the delivery quality of the packets it carries on behalf of its users the way the telephone network could. With the PSTN, you weren’t guaranteed that your call would go through, but when you successfully connected, your call always had the same quality. This all had to do with the way the PSTN managed resources; quality and capacity didn’t vary, which not only meant your call was never degraded, but also that its quality would never improve, even when the network was very lightly loaded.
This was a fine tradeoff to make for phone calls but it stinks for computers, where you sometimes need a ton of capacity for a couple of seconds because you’re loading a web page, or where you need a healthy amount of capacity for a couple of hours to watch a movie. These are entirely different kinds of networks, but our regulators want to treat them the same way. There is no way this approach can end in joy.
Statistical sharing – the principle that makes ‘always on’ mass connectivity economically feasible – is also the key cause of variability in delivered service quality.
The key to the Internet’s combination of high performance and low cost is its ability to engage in a game of chance at every switching point in the network; if every connection were guaranteed to run at the network’s peak advertised rate at all times, the cost would be 100 times higher, more or less. The key to the Internet is statistical sharing:
Performance, however, has many aspects that act as a limit. Geographical distance defines the minimum delay. Communication technology sets limits on the time to send a packet and the total transmission capacity. Statistical sharing of resources limits the capacity available to any one stream of packets. The design, technology and deployment of a communications network – its structure – sets the parameters for a best-case (minimum delay, minimal loss) performance at a given capacity. This is what the network ‘supplies’, and this supply is then shared between all the users and uses of the network. Sharing can only reduce the performance and/or the capacity for any individual application/service.
Sharing has two implications that no regulator properly grasps. We want sharing to be fair, but we don’t understand what “fair” means in a wild world like the Internet; and we want to be able to enforce a fairness rule, which means we have to be able to detect unfair management.
We can define “fair” sharing in three ways that have their shortcomings: per user fairness, per flow fairness, and per application fairness. Per user fairness means every user gets the same share, but that’s no good if users aren’t doing the same thing. Per flow (TCP connection would be a flow) makes more sense, but it falls apart when we realize that some applications use multiple TCP connections and some don’t. Per application fairness makes the most sense because it says VoIP calls should be treated the same way, video streaming sessions should be treated the same way, and peer-to-peer file transfers should all be treated the same way, but the FCC has declared this kind a fairness a “discrimination” that’s not allowed. The FCC’s networking guru, Barbara Van Schewick, insists on “application agnostic” traffic management and the FCC has followed her order hence we don’t have a fair Internet:
Instead, regulators or legislators should adopt a non-discrimination rule that clearly bans application-specific discrimination, but allows application-agnostic discrimination. (Again, I use “applications” as shorthand for “applications, content, services, and uses.”) Discrimination is application-specific if it is based on application or class of application, or, in other words, if it is based on criteria that depend on an application’s characteristics (“application-specific criteria”).[page 52]
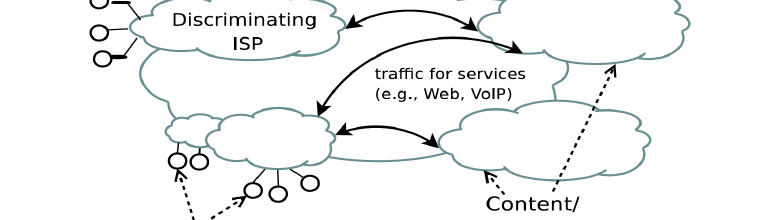
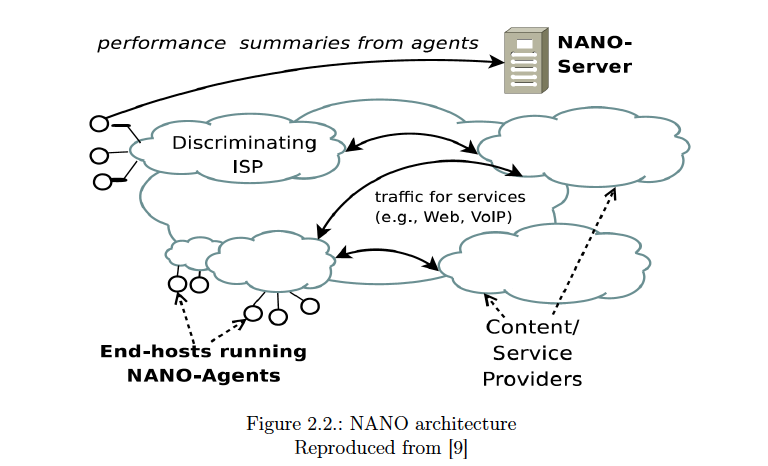
PNS proves that such a rule is unenforceable because application-specific discrimination isn’t detectable by any known tool, whether it’s NetPolice, NANO, DiffProbe, Glasnost, ShaperProbe, or ChkDiff. ChkDiff comes the closest, but it’s no longer being developed, and none of the others can find traffic management applied at different points on the path between client and server. This is because test tools for SPM networks share a common error:
The general assumption made in most [traffic management detection] approaches is that TM is the cause of differentiation in service. This is a narrow approach that does not seek to understand the factors influencing the performance of applications and protocols, but rather aims to ‘prove’ the hypothesis that ‘the ISP’ is restricting the delivered service to some degree. This is done by trying to disprove the ‘null hypothesis’ that no differentiation is taking place. Thus TMD techniques typically fall into the general category of statistical hypothesis testing. Such testing depends on being able to conclude that any differences in the resulting outcome can be unambiguously attributed to a constructed distinction between a ‘test’ and a ‘control’. It is important to show that such differences are not due to some other ‘confounding’ factor that would result in false positive/negative results. In the absence of a comprehensive model of the factors affecting performance, the methodology is to control as many potential confounding factors as possible, and deal with others by means of statistics. [page 39]
Oops. So what exactly is the point of banning a practice that can’t be detected in any case? It’s unclear.
These questions arise in the UK, however, because that country prefers to permit a wider range of traffic management than the FCC will allow in the US, and even allow operators to charge for prioritization. The conclusion that PNS offers suggests that the goal is worthy even if the (academic) tools aren’t up to the challenge:
TMD needs to be considered in relation to a broader framework for evaluating network performance. This framework should encompass two aspects. The first would be application specific demands, captured in a way that is unbiased, objective, verifiable and adaptable to new applications as they appear. This could be used to ascertain the demand profile of key network applications, which would give operators more visibility of what performance they should support, and OTT suppliers encouragement to produce “better” applications (imposing a lower demand on the network). The second would be a system of measurement for service delivery that could be unequivocally related to application needs. This would be necessary if one wished to know if a particular network service was fit-for-purpose with respect to an particular application. This measurement system would need to deal with the heterogeneous nature of the supply chain by reliably locating performance impairments whilst avoiding unreasonable loads on the network. Due to significant boundaries along the end-to-end path, responsibility could only be ascribed to commercial entities if these needs were met. A development of the tomographic approaches discussed in §2.3.7, combined with a generic network performance measure such as [delta]Q (outlined in Appendix A) has the potential to do this. TMD could then become a way to fill in any gaps in this overall framework7.
The UK appears poised to leap ahead of the US in broadband policy; all it needs to do is operationalize PNS’s insights. Read the paper to understand why.